Firebird for the database expert: Episode 3 - On disk consistency
<< Firebird for the database expert: episode 2 - Page types | Database technology articles | Firebird for the database expert: episode 4 - OAT, OIT and sweep >>
Firebird for the database expert: Episode 3 - On disk consistency
By Ann Harrison
Unlike most databases, Firebird has no external journal file or log for recovery from transaction or system crashes. The database is its own log. After a system crash, productive work begins as soon as the server restarts. Changes made by transactions that failed are removed automatically and transparently (see Record versions as an undo log). One necessary precondition for instant recovery is that the disk image of the database must always be consistent. Firebird achieves that consistency by tracking relationships between database pages and writing pages in an order that mainatains those dependencies. The ordering is called careful write.
On disk consistency
Reduced to its essence, the careful write means that the database on disk will always be internally consistent. More pragmatically, when the system writes a page that references another page, that other page must have been written previously in a state that supports the reference. Before writing a page that has a pointer from a record to its back version on another page, the system must have written that other page. Before writing out a new data page, the system must write out a version of a page inventory page (PIP) that shows the page is in use. The new data page has to be on disk, formatted and happy, before the table's pointer page that references the new page can be written.
Inter-page relationships are handled in the code through a dependency graph in the cache manager. Before a page is written, the cache manager checks the graph and writes out all pages that page depends on. If a change will create a loop in the graph, the cache manager immediately writes as many pages as necessary to avoid the loop.
The tricky bits are identifying dependencies and avoiding the impossible situation - well, those and keeping the system fast. Identifying dependencies just requires meticulous coding. If you have to put a record back version on a different page from the main version, the page with the pointer has a dependency on the page with the back version. If you allocate a new data page, that data page has a dependency on the PIP that records whether the page is in use, and the pointer page that ties the data page into the table has a dependency on the data page. For more information on page allocation see Where do data pages come from?
The impossible situation is one where pages point to each other in a way that can't be separated. Two pages can point to each other - you can have a primary record version on page 214 with its back version on page 215 and a different record with its primary version on page 215 and a back version on 214. The chances that the cache manager will find a cycle in the dependency graph are high, and one page may need to be written twice in the process of flushing the pages out, but it works because the two relationships are separable.
If, on the other hand, you need a double-linked chain of pages - index pages come to mind, there is no separable relationship. Each page depends on the other and neither can be written first. In fact, Firebird index pages are double-linked, but the reverse link (high to low in a descending index) is handled as unreliable. It's used in recombining index pages from which values have been removed, but not for backward data scans. The architecture group is currently discussing ways to make the reverse link reliable enough for retrieving data, but we haven't agreed on a solution.
For those who haven't spent an embarrassing part of their adult lives worrying about on disk consistency and double-linked lists, let me try to explain.
Assume that each index page can hold only four values - instead of the hundreds that it actually holds. Consider the leaf level of an an index that consists of pages 124, 125, and 126 in that order. The next level in the index is represented as page 213. Each index page has a pointer to its left and right neighbor. The neighbors of page 213 are omitted as boring. Page 124 holds A, B, D; page 125 holds F, H, J, L and page 126 holds N, P, R. Now you want to add a new entry to the index. It has to be put on page 125, but page 125 is full, so you need to add a new page between 125 and 126. The color key for diagrams can be found at the end of this article.
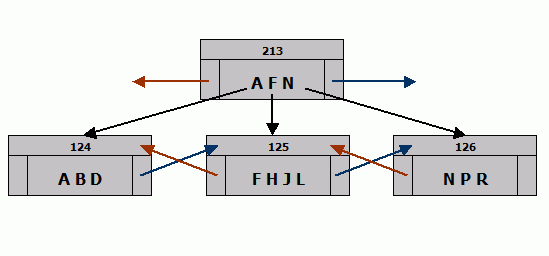
You want to store K.
The way the index code handles this sort of problem is:
- Read the current PIP (page information page) to find a free page - lets say it's 234.
- Change the PIP to reflect that page 234 is not available.
- Set up a dependency so that PIP will be written before the new index page.
- Format a buffer to look like an index page with the page number 234.
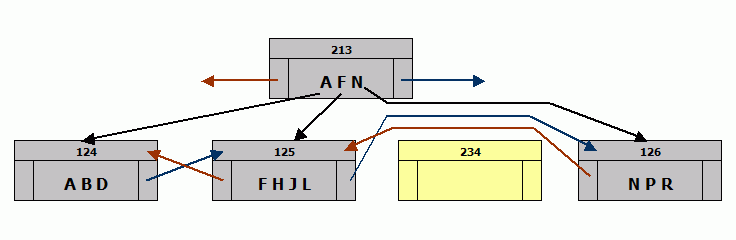
- Copy half the index entries - entries J, K, and L - from the page that overflowed onto page 234.
- Copy the pointer to the next index page from the page that overflowed (125) onto the new page (234).
- Make the new page (234) point backward to the page that overflowed (125).
- Mark page 234 to be written. Now page 234 can be written if it is needed by another transaction, as long as the PIP is written first.
At this point, page 125 still points forward to 126, which points backward to 125. There are two copies of the index entries for J & K, but that doesn't matter because there's no way to get to page 234 - it's not in the upper index level yet and will be skipped by a scan, regardless of direction.
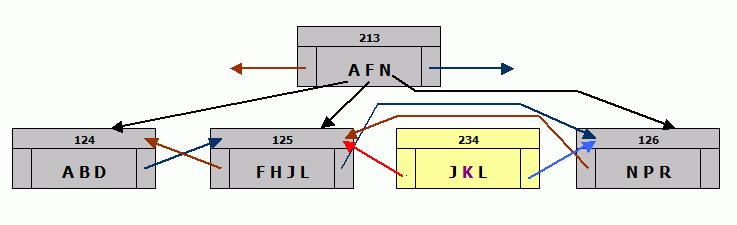
- Fix the upper levels so they include the first value of the new page. That change may cause an upper level page to overflow, resulting in the same series of steps at that level, and so on up to the top. If the very top page splits, the index gets a new level.
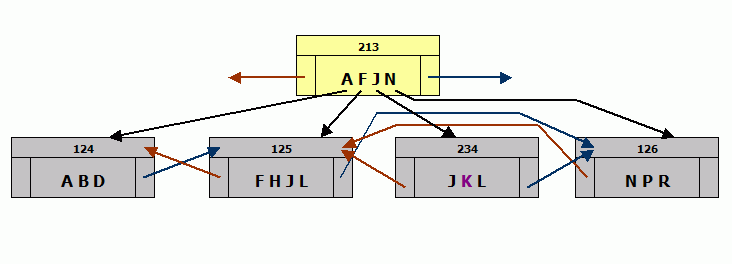
Now, the upper level contains an entry for J points to 234 rather than 125. Scans still work because anything that starts lower than J will skip node 246 and anything higher than J will skip 125.
- Remove the copied index entries from the page that overflowed and change its back pointer to point to the new page.
- Write that page.
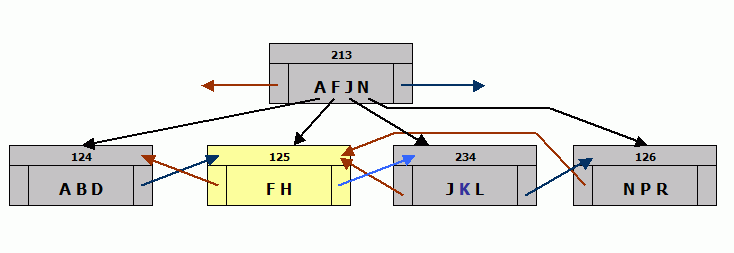
A forward scan still works, but a backward scan that starts with N or higher will never see the values J and L. The code that handles recombinations does a lot of sanity checking and quits when it sees a problem. That strategy doesn't work for record retrievals.
- Fix the back pointer on the page after the new page to point to the new page.
Now the structure works again.
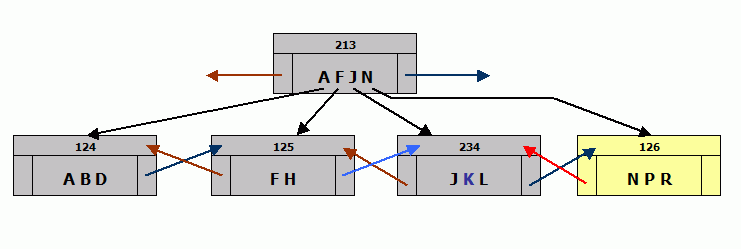
There are a couple of unavoidable awkward situations that occur during page allocation and release, and result in orphan pages and orphan back versions. Orphans are wasted space but do not affect the integrity of the database.
At the page level, GFIX will sometimes report orphan pages after a crash. If the system crashes after a page has been allocated and the PIP written, but before the pointer page that makes the data page part of the table has been written, that data page becomes an orphan. Note that the data on that page is uncommitted because the change that commits a transaction - writing the transaction inventory page with the transaction marked committed - does not happen until all page that were created by the transaction have been written.
If the system crashes after a pointer page has been written, removing an empty data page from a table, but before the PIP has been written to reflect that the page is free.
If the system crashes in the middle of dropping an index or table, GFIX may find lots of orphan pages - a single write releases all the pages that were part of the table or index, and that write must happen before any of the PIPs can be changed.
Back versions must be written before the record that points to them and can not be removed until after the pointer to them has been cleared. A crash between those steps makes the back version an orphan - it occupies space but is not connected to a record.
Key to diagram colors

This paper was written by Ann Harrison in June 2005, and is copyright Ms. Harrison and IBPhoenix.
See also:
Database Corruption
Preventing data loss
Alternative database repair methods
Database validation
Firebird database housekeeping utility
back to top of page
<< Firebird for the database expert: episode 2 - Page types | Database technology articles | Firebird for the database expert: episode 4 - OAT, OIT and sweep >>




