Firebird replicated
Source: Firebird Conference 2009 in Munich; Holger Klemt.
Replication is the distribution of data stored in one database to other databases. There are different reasons for implementing a replication, for example, business continuance - you have several offices in one or more countries, real time data access for your field staff, and of course, disaster recovery. Narrowing down the specific reason for replication will dictate not only the type of replication that is needed to solve the business problem, but will also help when making infrastructure decisions such as what bandwidth is required to replicate the data.
Replication works with every data type and object available in Firebird or InterBase®.
Replication types
Clustering is the connection of two or more servers, which do the same job at the same time. For example a company has 200 users, 100 are working on one server and 100 on the other. Both should be able to write the data to the database, and the databases on each of the two database servers should synchronize the data between them. This can be handled in an online replication where the data is immediately sent to the replicated target. It is not a true cluster, because you have to take care which of the servers you are connected to, and delays in replication occur if one of the servers does not respond. Due to the event alerter used in the scripts, it is however a very fast way to exchange the data between the partners. It allows both offline (only connect once a day, once a week etc.) and online replication.
In an offline situation, for example, an insurance company field representative works offline all day and returns to the office in the evening, when all the new insurance contracts should be sent automatically to the insurance company head office over the internet. In this environment you will often encounter the problem that some staff will occasionally be offline for more than three weeks or so, because they are on holiday or ill. If this amount of still-time is during a bidirectional replication, you will need some type of stack of jobs that have to be replicated when the worker is online again.
The replication solutions that we have implemented are not out of the box replications. We cannot simply run a single script, because we know that typical databases have different architectures, different implementations, different datatypes and so on.
Simple replication example
IBExpert will be used here to demonstrate what is happening with the database. Using a simple database to show you how the basic objects should be created, you will learn the basic concepts that are required for implementing a replication. To illustrate this I will first create a database, C:\REPL1.FDB.
In order to replicate data, we first need to create some. In the SQL Editor I create a simple table with a primary key. I also add a NAME VARCHAR(80) and CITY VARCHAR(40) and commit my table.
The basic implementation of a simple replication is the creation of something similar to a transaction log. Although Firebird does not implement a transaction log itself, you can create it yourself. To prepare for the creation of a transaction log I first edit the field ID – autoincrement, creating a generator, ID, which I use for all tables.
You don't need to worry about overflow by using just one single generator; if you are working with a 32-bit ID datatype INTEGER, you can take one number per second, this will take 130 years until you get an overflow – which will no longer be your problem! And if you’re working with SQL dialect 3, you can use 64-bit generator values, which can generate 4 billion values each second, and it will still be valid for 130 years. And this solution prevents any primary key conflicts arising.
Then I create a trigger using the default constellation offered by IBExpert, to automatically generate an ID number each time a data set is added:
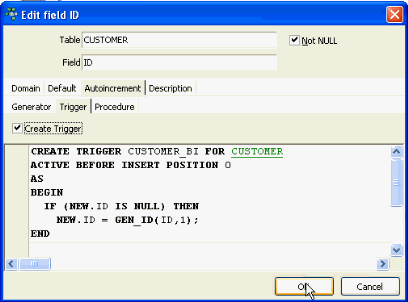
Then I add an INSERT statement to add some data:

Creating the log table
To log the actions on this machine we should automate the storage of all actions performed on this database. So create a table, R$LOG:
create table R$LOG (ID bigint, not null, primary key, sql blob sub_type text, user Varchar(32) default current_user, ts timestamp default current_timestamp tid integer default current_transaction)
The transaction ID has been included so that this table can be used not only for replication but also for an undo and redo log. This will be illustrated a little later on, based on a new column, UNDO.
For example, when doing an INSERT statement, we can simply say that the undo is the DELETE, and if we are doing a DELETE, the undo is a simple INSERT. If we are doing an UPDATE OLD VALUE = NEW VALUE, we can say the undo value is OLD VALUE = NEW VALUE. However you need to do some automization in your application to make this a little more comfortable to use.
In a replicated environment, for a single direction replicated environment, you need a way to create global, unique primary keys. And a global unique primary key in a database with, for example, 950 tables and 950 different generators – is extremely elaborate to synchronize them between databases. To synchronise one generator across all databases is an much simpler. And when you’re working with two different databases: in one database the generator is set to 1 billion and the second one is set to 2 billion; every new record is based on this offset where the local database is currently working, and you can exchange all data between all these databases without any problem because they will not violate any other primary key. There are 4 billion x 4 billion possible starting values, so it’s not a problem even with databases with hundreds of users and a high data manipulation load. We have a customer project with 6,500 laptops installed for insurance agents, and they all replicate to the same engine.
Creating the AFTER INSERT trigger
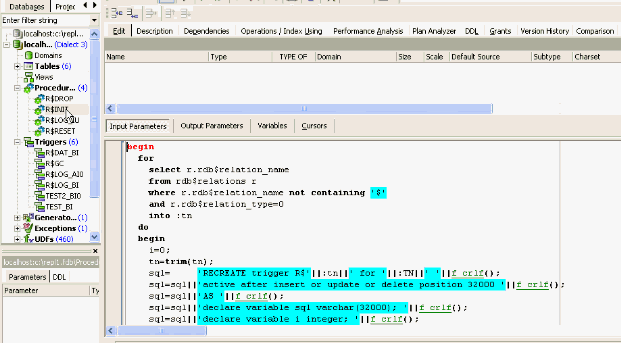
I create an AFTER INSERT trigger on the CUSTOMER table specifying the trigger position, for example, at 32000, to leave open the possibility for all other triggers to run before it. I name the trigger CUSTOMER$IU, and I use the INSERT OR UPDATE TRIGGER statement. IBExpert offers the possibility to work in lazy mode, for those people who do not want to repeatedly write the header of a trigger or procedure each time they create a new object:
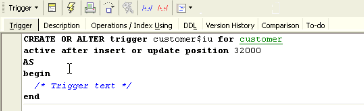
One of the nicest features of this replication implementation is the INSERT OR UPDATE statement, because I don’t have to think each time about whether this an INSERT or an UPDATE. Now I want to create a simple variable for the SQL implementation. In order to avoid problems I recommend always prefixing variables, e.g. with x, to ensure a variable isn’t accidentally given the same name as a column.
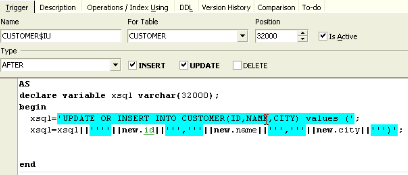
I create a VARCHAR(32000). I then start the INSERT OR UPDATE and then comes the part where I need a constant for this table. When I start my replication implementation, I write my first trigger based on rules that I already have in mind. But these rules will later be created automatically by a stored procedure. I simply write a stored procedure that writes triggers using EXECUTE STATEMENT.
Next we need values:
xsql=xsql
combined with the following (string sign):
xsql=xsql ||’’’’||
You can probably make this a little neater, but what I need now is a NEW.ID. For the next step I use the string marker again. The string marker has the problem that I always have to use two to get one. This looks really interesting when you are later writing a stored procedure that writes triggers because, as we need two in the trigger, we need four in the stored procedure, which is sometimes difficult to debug, and not particularly easy to read.
I then combine the NEW.ID with NEW.NAME and NEW.CITY, closing it and finally closing the variable as well with a ";":
Then I add a check clause: if the CURRENT_USER is not the REPL user, (because I use the REPL user internally for sending data from one database to another), then execute this:
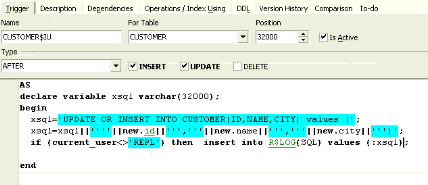
If I now go to my data record, IBExpert KG, and say IBExpert KG is no longer a KG but a GmbH, I make the change, commit and then take a look at my log file. In the R$LOG table I can see my statement:
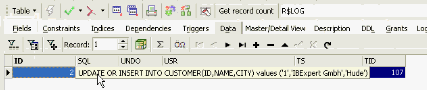
Each time I make an UPDATE OR INSERT to my CUSTOMER table and commit, it is displayed as a dataset in the R$LOG table.
Now you need a string replace functionality, because when any of the records have a single quote inside them you have to double them, i.e. Single quotes are replaced by double single quotes. Most of the time I personally use a UDF for this, simply for historic reasons.
But we need to think about some other things as well. The next step is not only having data with single quotes inside the dataset but also to have data with empty fields, for example, Bauzentrum with no CITY returns NULL:
This has happened because when you combine NEW.CITY which is a NULL value with a string, the resulting string is NULL. So the NULL value must also be handled in a different way. In this trigger I have used COALESCE: if a name exists, it is taken, otherwise the string NULL is taken:
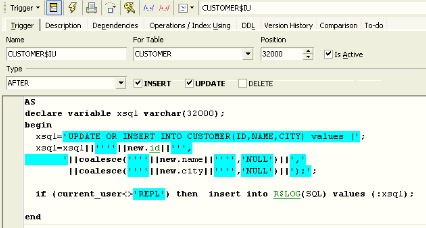
If I now make an alteration to a data set leaving a field empty, the statement now appears correctly in R$LOG.
The next step to consider is the correct handling of integers, based on their type, because when you have numeric values, it makes no sense to have single quotes around them. Internally you can do that in Firebird, but it’s not always a good idea if you may need to use the same replication environment for replicating data to other database platforms. We have for example replicated data from Firebird to a IBM AS/400 and to an Oracle server. Especially the AS/400 has a number of issues, for example, you cannot quote integer values.
We can now add some SELECTs based on the system tables. For example:
select * from rdb$relation_fields
where we see the relation ID, CITY, NAME and so on:
And it shows which domains the fields are based on.
select * from rdb$fields
shows the domain information:
One of the nice things about Firebird is that we can access all the information in the database. Writing this trigger is a once-only job, which minimizes the possibilities of making mistakes, even if you need to spend the time to check you have taken all possibilities and all datatypes into consideration. Writing a new trigger each time a table is created opens up too many holes for errors. And working with this database in a customer enviroment, when you have for example, 6,500 laptops running, and you want to update the database with a new object, you may need to drop this trigger, because it might have references to this NEW.ID column or NEW.CITY, NEW.NAME and so on. If you have this information here inside the trigger already connected and bound to the column, you cannot change this column or drop it.
You will of course also need to carefully consider how to deal with any eventual update conflicts. An example can be illustrated based on German addresses, where post box addresses have different ZIP codes to the street addresses. User A mistakenly adds an address with the post box number and the ZIP code for the street address. User B notices this and alters the post box number to the street name in order to fit correctly with the ZIP code. In the meantime User A has noticed his mistake and alters the ZIP code to fit correctly with the post box number. Both operations are correct but the AFTER UPDATE triggers will alter the data so that the end result is still wrong. For such situations you will need to carefully consider how you implement rules.
Creating procedures for metadata updates
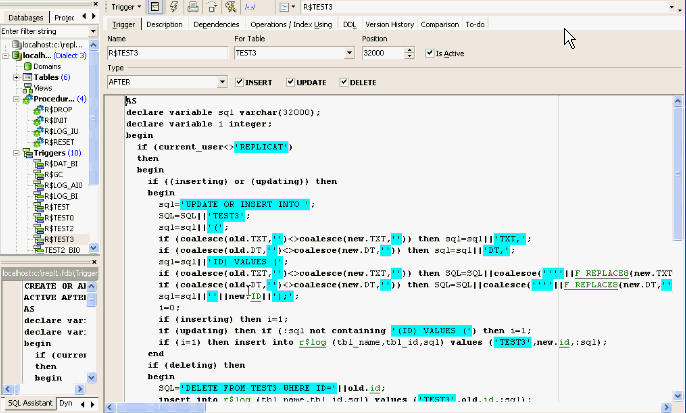
Another issue that needs to be taken into consideration is the replication of metadata alterations; you cannot make any changes in a table if a trigger is working on it. So you need a procedure that drops all triggers and creates all the database objects that are required for the replication, and a second procedure to drop all the objects you no longer need and then recreate the triggers required for the replication. When you want to update a database you then simply need to do a DROP [OBJECTS], update your database, create new tables and so on, and initialize the replication triggers, which are created directly from the information we have in the system tables, so therefore will include all new metadata information automatically.
Let’s look at an R$DROP procedure. There are 6 triggers which are used internally:
When I create a new table TEST, commit and then run the R$INIT procedure, it finds new entries in RDB$RELATIONS, when I refresh IBExpert, I now find 10 triggers including one for my new TEST table:
This information is implemented internally. When I now add some data, we can see that the global generator was also used for this table. If we look at the R$LOG table, we at see an UPDATE OR INSERT, and that the date in the third column was updated:

So this construction not only allows you to replicate and distribute data but also metadata. After we have created this new table in the new REPL1.FDB with the specific logging inside, we need to proceed to the next step to understand how we manage to distribute the data from one database to another.
Recording database alterations
When we look at the R$LOG table in REPL1.FDB we see here not only the user name but also the timestamp.TS and the table ID, TBL_ID:

But which table ID was processed by this log operation? When I want to see the history of a specific record I can do a simple SELECT on this table, based on a global unique ID. When I want, for example, to send data from my local replication system to another database, I simply have to look for locally created data. You may need to include rules, for example that all data be sent to a central server and the central server should send the same data, or parts of it according to specific rules (e.g. depending on ZIP code, region, product group or similar) to the other laptops. So it’s often helpful if you know where the data was created. This is what I use the DB column for. I also have blob column which is used for storing blob data.
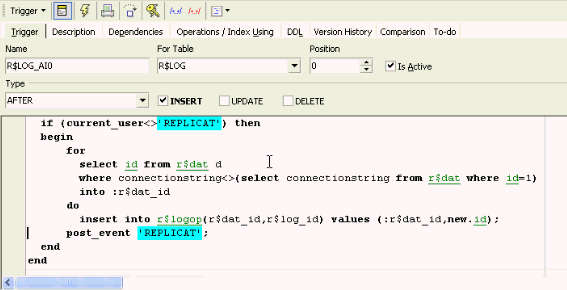
In the R$LOG table I use the following: I have an AFTER INSERT trigger, R$LOG_AI0, and I go through the R$DAT table, and take all the ID values where the connection string is not the local connection string (the local connection string always has the ID 1), and for each of these records I insert into a table, R$LOGOP(eration), a record with the target, which of the R$DAT entries and which of the R$LOG table IDs that should be transmitted:
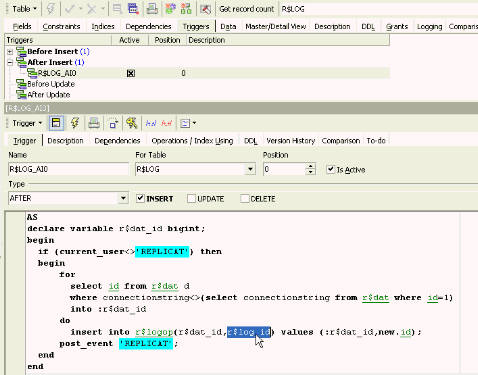
Let’s look at the R$DAT and how it is implemented. I always have a list of replication targets, and I always have the number 1 with the local database string:

In Firebird 2.1 we can see in the MONITOR table that this is the current database, but in older versions we cannot see that so easily. This construction also works with Firebird 1.5 and Firebird 2. And in the R$LOGOP for example, we see the 100,000,000,000 and the 200,000,000,000; in the R$LOGOP table we now find 2 entries and in the transaction log this record with this number should be transmitted to the database connection string with 100,000,000,000.
Since I currently only have two databases here, it simply adds two 64-bit integer values in this table, and if I transmit the data from my database to a defined database target and this was successful, I do not delete the log entry; I simply delete this record in R$DAT. And deleting this record is not a big deal for the Firebird database, because it’s not the same amount of work as having to, for example, update existing records: last updated or last replicated or whatever. We simply have to find out how to send all the records from one database to another.
Replicating the data
This is the last step: I will demonstrate it using the the scripting possibilities that are included in IBExpert although it can be done in any scripting language such as PERL or PHP. This is a script I use for sending data from one database to another:
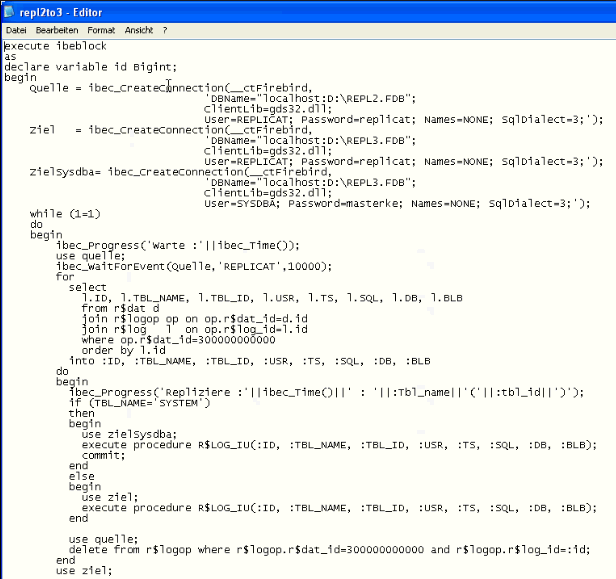
This is the script that replicates data from REPL2.FDB to REPL3.FDB, although there are simpler possibilities now available in newer IBExpert versions using variables. This script creates a connection with the source (Quelle) and its user REPLICAT, and with the target (Ziel) and its user REPLICAT and also the target SYSDBA, ZielSysdba, so that metadata can also be replicated if necessary. In an endless loop waits for a specific amount of time, opens the source database, and waits for an event. The event name is fired by a trigger on the R$LOG table (R$LOG_AIO), we post a simple event with the name ‘REPLICAT’:
The IBExpert script can be used as a batch file or in IBExpert interactively. So we simply wait for the event, ibec_WaitForEvent, if it does not come within 10 seconds, the operation is exited and goes to the next line. When an event comes along, it does a SELECT on R$DAT, R$LOGOP and the R$LOG tables, and the R$LOG table uses a constant,
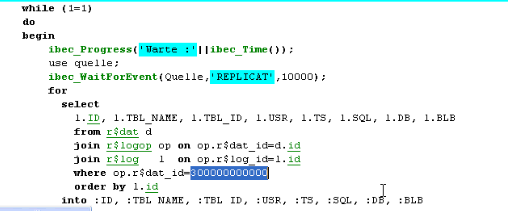
this is the target, 3000000000, and I want to see the data for the target 3000000000. I put it into variables:

and then I replicate this table with this ID.

If TBL_NAME is SYSTEM we need to work with the SYSDBA. So simply sending operations, for example, a CREATE TABLE, DROP TABLE or whatever, can be done by inserting a specific command into R$LOG table and for the TBL_NAME, it would be SYSTEM. In that case the replication will automatically do whatever operation you want it to do as the SYSDBA user. This is necessary as in this construction the REPLICAT user is not the database owner. If it is the table SYSTEM, use target SYSDBA user and execute the R$LOG_IU, where the operation is executed internally. If it is not SYSTEM use the typical target ZIEL and execute it here as the user REPLICAT.

After that open the source Quelle, delete the log operation entry, then commit the delete operation on the target and finally commit the deletion on the source. And if something happens, for example, the database connection is lost, we can no longer do the commit. The script will immediately stop working and in an endless loop (in a batch file for example) will try to connect again. Once it has been restarted automatically, it will try to reconnect to the database, try to find out which data from the source must be sent to the target, and if it results in an error again, it will stop immediately and rerun again.
So simply by pulling out your network cable or similar, the same operation will work in an endless loop, because the script will be started automatically, and when the target is available again, it will send the data to this target. And at the end of the script:
all connections are closed.
The script can of course be easily modified for further replications.
If you have set up a distributed database environment, you should plan metadata updates carefully. For example, if you have a table that is already used by a replication, and it enters some data into the replication table, it will definitely raise an exception if it cannot insert into a table that doesn’t exist elsewhere.
When you are doing a WAIT FOR EVENT at the beginning of the script, you will need to wait 10 seconds once, but after that it should transmit directly.
Automating script execution
This can be easily demonstrated outside IBExpert by running IBEScript (a command-line version of IBExpert) – it can be used to implement all scripts that can also be executed in IBExpert:

When I make some changes in REPL1.FDB, we can immediately see the replications:
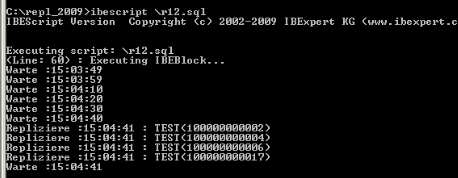
It always waits for the commit statement before sending the event. Following the commit it immediately replicates the changes I have made.
Individual scripts can handle multi-directional replication, for example, A to B, A to C, B to A, B to C, C to A, C to B.
What you see here is the possibility to exchange the data at runtime based on the event alerter. But you can also wait to exchange the data, until, for example, a laptop is online again. And when the laptop is online, you can do a kind of push replication, so the server – where the database is and where the records are created, sends all records to be replicated to all other clients by individual jobs. Such a simple implementation can, for example, be controlled by the Task Manager in Windows or in any other environment.
Following a successful replication the log entries in R$LOG are automatically deleted by the garbage collector trigger, R$GC, which is a database trigger and which simply does a disconnect and deletes all log entries:
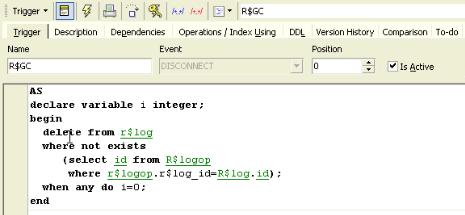
In this way the R$LOG table is always emptied following a successful replication.
Although I have only demonstrated a unidirectional replication here, you can see that a bidirectional replication can be done in the same way. Multi-directional replication or multi-target replication, for example, if you are working with 3, 4 or 5 databases, is also possible using the same technology.
One of the things that is important is that the current way of exchanging the data only by using a script and executing each statement individually and committing each statement individually, might be a little bit of a problem when you have extremely large data updates, for example, price list changes with 200,000 revised prices, which will of course give you 200,000 entries in the replication log. A possible solution for such large data quantities is to make an extract of the LOG table, with some simple commands, where the REPL$LOG table is stored in a text file, zipped using the 7z compressor, and uploaded in a blob field. Executed in this way, it can be sent to the replication partner much quicker, as it is almost 100 times smaller. We know from experience based on this construction, that a typical replication process of about 100,000 changes takes about three minutes; downloading all the data, unpacking the data, executing the script.
Optimize your data model: the smaller the individual tables the smaller the replication file (e.g. it makes a huge difference if one field is updated, how big the whole table is. It's obvious that a table with threee or four fields can be transmitted much quicker than a table with thirty or forty fields. And it is often wise to store blob data separately, as this is often static information. This way your data can be regularly replicated and updated; the blob information is only transmitted when new, altered or deleted blob data occurs.
When you split up large tables into smaller normalized ones, you can replace the original tables with updatable views. That way older applications do not need to be alterd and can still mainpulate the old structure. Any new applications should, of course, use the new structure.
Incorporating new computers in the replication group
Quite simply: backup up an existing database and restore to the new connection. Set the generator ID number to the new offset, change the value in the R$DAT table. Delete all entries in the R$LOG table, because they are not needed. Finally adapt the scripts using search and replace.
Conclusion
So you can see that implementing a replication is not some big miracle; it is something that every developer can do. Setting up a replication engine is a really simple programming job based on the technology you have with Firebird; even though it is initially very time-consuming. If you were to do the same implementation in a different database environment however, you would encounter many more problems. This solution is flexible; you can define the rules as you wish, to specify which data is sent where. And it is fast: using stored procedures you can execute up to 200,000 changes a second (although if you have that amount of manipulation in your database you will almost certainly encounter problems elsewhere!).
See also:
Distributed applications with Firebird
Bidirectional replication for InterBase and Firebird
back to top of page
<< Import and export using IBExpert (2) | Database technology articles | Distributed applications with Firebird >>




